Automatiser la détection de la manipulation de l'information en cas réel
Sommaire
Nathan DUNAND (auteur) - Jean SEVAUX - Clément LAISNÉ - Corentin HUVELIN
Une décision commune de Washington et Moscou, qui gèlerait le conflit [Ukrainien]. Je n’y crois pas. Nous sommes au début d’un cycle de guerre froide qui va durer trente ou cinquante ans. Il y aura des guerres économiques, des guerres informationnelles et des conflits délocalisés.
Amiral Pascal Ausseur dirige la Fondation méditerranéenne d’études stratégiques. 22 septembre 2022 dans l’Express
Abstract #
Cet article présente un projet d’ingénierie visant à automatiser la détection de la manipulation de l’information. Il se concentre sur la lutte informatique d’influence, qui désigne les actions visant à manipuler l’opinion publique via les médias numériques et les réseaux sociaux. L’objectif est de développer un outil capable de détecter la désinformation en ligne à partir d’un jeu de données. Le processus de détection doit être résilient, rapide, expliquable et produire des informations pertinentes pour les analystes.
Le projet se base sur des indicateurs issus de la littérature scientifique tels que le nombre de mots, la longueur des tweets, la fréquence d’utilisation des hashtags, le score de sentiment, etc. Une méthodologie en trois étapes (homogénéisation, enrichissement et corrélation) est utilisée pour traiter les données et produire une visualisation. Une comparaison entre trois datasets traités par notre outil est effectuée et permet de discriminer des comptes et des datasets suspicieux.
Des perspectives d’amélioration sont également discutées, notamment l’extension de la collecte de données à d’autres plateformes et langues, ainsi que l’utilisation de l’apprentissage automatique pour la classification des comptes légitimes et non légitimes.
Introduction #
Cet article synthétise notre projet de quatrième année d’école d’ingénieur. Il vise à exposer les réalisations, les résultats, ainsi que les problèmes auxquels nous avons été confrontés pendant ce projet.
Il s’inscrit dans la formation d’ingénieur de quatrième année. Il a pour objectif de nous confronter à des problématiques réelles, que nous explorons avec une démarche ingénieur, dans le but de présenter notre projet et nos résultats. La thématique est à notre initiative, un professeur nous a aiguillé lors de rendus réguliers durant cette année.
La Lutte d’Influence Informatique (L2I) fait référence aux actions employées par les acteurs étatiques, activistes ou organisations pour manipuler ou influencer l’opinion publique à travers les médias numériques ou les réseaux sociaux.
Cela peut impliquer l’utilisation de techniques de désinformation, de diffusion de fausses informations, de manipulation des réseaux sociaux, de piratage ou de création de faux profils. Les objectifs pouvant être de façonner les perceptions, semer la confusion ou influencer des comportements en ligne.
État de l’art #
La détection de la désinformation en ligne est détectable avec des algorithmes de Deep Learning 1, ils offrent de bons résultats.
Cependant, il est difficile de trouver des jeux de données pertinents, à jour, et suffisamment larges. Les algorithmes de détections doivent dorénavant se baser sur le contenu des auteurs et non uniquement leur comportement. Pour cela, certains indicateurs sont plus pertinents que d’autres 3. Cette approche comporte deux avantages, elle permet de répondre plus efficacement à l’adaptation des acteurs de la désinformation et de construire des solutions indépendantes du réseau social étudié, Twitter étant largement surreprésenté. Plus spécifiquement, le traitement automatique du langage naturel (NLP) ainsi que de l’apprentissage non-supervisé sont des outils pertinents 2, 4 et 5.
Objectif #
L’objectif du projet est de permettre une détection de la désinformation en ligne. Nous souhaitons, à partir d’un jeu de données (dataset), produire des indicateurs qui permettront à un analyste d’investiguer et de catégoriser l’information. Le processus doit être résilient, rapide, expliquable et produire des informations pertinentes. L’analyste disposera alors d’un outil qui lui permettra à la fois d’avoir une vue globale sur le jeu de données, mais également une vue plus fine si de la manipulation est suspectée.
A noter que nous ne prenons en compte ni la collecte de données, ni l’interprétation de ces dernières. Cela relève d’autres défis et nécéssiterait un projet à part entière.
Contraintes #
Ce projet se déroulant sur une année scolaire en alternance, la principale contrainte est temporelle. Notre envie initiale était d’étendre notre projet jusqu’à la collecte de données sur Twitter. Cependant, le rachat du réseau social par Elon Musk nous a impacté. En effet, son changement de politique à l’égard de l’API Twitter et des jeux de données issus de la plateforme ne nous permettait plus d’obtenir de la donnée en temps réel, indispensable à notre projet. Nous avons construit un dataset (jeu de données) contenant de la désinformation mais aussi des tweets légitimes que nous avons assemblés afin de tester notre outil. Ce processus d’assemblage est détaillé plus bas dans l’article.
Le dataset #
Pour disposer de données, nous avons récolté un dataset qui est utilisé dans la littérature scientifique afin de tester des algorithmes de détection de la désinformation. Ce dataset est imparfait pour notre cas d’usage. En effet, il ne contient que des tweets identifiés comme étant issus de campagne de désinformation. Ces tweets sont pour nous du signal ; ce ce que nous devrions détecter. Il nous manque du “bruit” ; des tweets légitimes.
Pour constituer un dataset qui contient du signal et du bruit, donc plus proche de la réalité, nous avons fusionné deux jeux de données. Le second dataset est issu d’une compétition de cybersécurité appellée TRACS. Dans ce tournois auquel certaines personnes de ce groupe ont participé, nous devions identifier des comptes faisant de la désinformation parmi des utilisateurs légitimes. Nous avons enlevé les robots de ce dataset et fusionnés les tweets restants avec notre signal.
Cependant, lors de la fusion, nous avons perdu de l’information. En effet, le dataset comportant notre signal dispose de bien plus de données que le second. Par exemple, il contient les dates des tweets, le nombre de followers du compte, etc… Cela nous a mis face à un choix :
soit nous remplissions le dataset bruité avec des données, cela implique un investissement en temps et le risque de le biaiser.
soit nous assumons réduire notre socle de données, quitte à passer à côté d’indicateurs intéressants. En d’autres termes, il s’agit de s’adapter au dataset qui comporte le moins de données, et à s’aligner sur lui.
Nous avons choisi la seconde option, par contrainte de temps, mais aussi pour ne pas empoisonner nos données.
Méthodologie #
De part la nature de notre projet, nous pouvons être ammenés à traiter des volumes de données conséquents. De plus, dans une optique d’industrialisation, il est nécessaire que notre processus de traitement des données puisse être mis à l’échelle ; c’est-à-dire qu’il puisse supporter un volume de données plus conséquent sans faillir. La big data est un champ scientifique qui répond à ces contraintes, notre projet s’inspire des méthodes utilisées dans cette discipline.
Le pipeline est une représentation abstraite de notre processus de traitement de données. Il se découpe en 3 étapes :
homogénéisation : vérification du type des données, de leur format, suppression e/o ajout de données.
enrichissement : première phase de calcul dans le but de produire plus de données à partir de celles existantes. Par exemple : nombre de hashtags d’un tweet, longueur moyenne des mots… utilisation d’algorithmes de Natural Language Processing (NLP) pour calculer un score de sentiment d’un tweet.
Le score de sentiment est un réel qui est compris entre -1 et +1. -1 étant un tweet considéré comme étant négatif et +1 comme positif. Une phrase positive étant par exemple : “Je trouve cette voiture très jolie.”. Un score de 0 est une phrase neutre. Attention cependant à l’interprétation de cette donnée ; un tweet ironique sera perçu comme positif par l’algorithme, alors qu’un humain le comprendra comme étant négatif. Par exemple : “Monsieur X est un politicien honnête, comme en atteste les nombreuses plaintes contre lui.”. De plus, l’algorithme que nous avons choisi ne permet d’effectuer ce type de calcul que sur de l’anglais.
- corrélation : seconde phase de calcul qui aggrège les données sur les auteurs des tweets et calcule, pour chaque auteurs, un ensemble d’indicateurs et leurs dérivées (voir la partie dédiée). Cette étape produit un fichier qui sera directement exploité par l’analyste grâce à un outil de visualisation. Elle utilise également de la NLP pour calculer la similarité moyenne des tweets d’un auteur. Cet algorithme produit un réel allant de 0, tous les tweets de l’auteur sont très différents, à 1, tous les tweets de l’auteur sont rigoureusement identiques. Il est important de noter que l’algorithme compare le sens des tweets et non une comparaison lettre par lettre.
Chaque étape produit un fichier en sortie, qui est réutilisé dans la phase suivante. Détaillons le processus complet sur un petit jeu de données.
NLP #
Cette partie s’addresse aux plus curieux en matière de NLP. Elle n’est pas nécessaire pour comprendre l’article. Nous assumons que vous possédez des notions dans ce domaine.
Nous avons utilisé le packahe Python nltk. Selon la littérature scientifique, il produit des résultats à l’état de l’art. Nous avions été orientés vers des modèles de type BERT, mais par manque de temps nous n’avons pas pu creuser plus avant les modèles. Nous avons choisi une technologie simple et rapide à implémenter. De plus, cette librairie permet de faire de l’analyse de sentiment, ainsi qu’un calcul de similarité.
Que ce soit pour l’analyse de sentiment ou le calcul de similarité, le processus comporte plusieurs étapes :
tokenisation : découpage du texte en “token”, à peu près équivalent à des mots.
application des “stop words” : suppression des mots non impactants sémantiquement (déterminants, prépositons…).
lemmatisation : réduction des mots à leur sens strict (exemple : “mangeons” va devenir “manger”).
réassemblage des tokens en textes.
application de l’algorithme de NLP.
Pour le calcul de similarité, nous calculons la matrice de similarité cosinus à partir des vecteurs TF-IDF. Ces méthodes sont également utilisés en fouilles de texte par des moteurs de recherche pour évaluer l’importance de termes dans un corpus. Voici le code que nous utilisons, certaines fonctions sont issues du package nltk :
similarity_matrix = cosine_similarity(tfidf_matrix)
# average similarity processing
similarity_score = similarity_matrix.sum() / (similarity_matrix.shape[0] * (similarity_matrix.shape[0]))
# reduce RAM usage
del similarity_matrix
del tfidf_matrix
del tokenized_contents
Afin de réduire l’usage de la RAM, nous supprimons certaines variables lourdes pour être sûr de libérer de la mémoire vive. Nous avons mesuré une baisse significative (plusieurs gigas de RAM en moins pour un dataset en entrée de 160Mo) de l’usage de la RAM suite à cette action. Cependant, de véritables tests doivent être menés afin de juger de la pertinance des trois dernières lignes.
Exemple #
Voici notre dataset qui regroupe trois tweets de deux utilisateurs différents. En réalité, le dataset en entrée contient plus de données mais tous les champs ne sont pas utilisés (voir la section précédente). Par simplification, nous ne montrons que les données utilisées par l’outil.
author,content,language
10_GOP,"""We have a sitting Democrat US Senator on trial for corruption and you've barely heard a peep from the mainstream media."" ~ @nedryun https://t.co/gh6g0D1oiC",English
10_GOP,"""We have a currently serving Democratic US senator facing corruption charges, yet there has been minimal coverages of it in the mainstream media."" ~ @nedryun https://t.co/gh6g0D1oiC",English
sonataz45,"""Just witnessed the most breathtaking sunset. Nature's artwork never fails to amaze me. #NatureBeauty #SunsetMagic""",English
L’homogénéisation ne produit aucun changement. Dans un cas réel, il aurait traduit toutes les dates dans un même format, remplit certains champs laissés vides, etc… Cette première étape est facultative pour notre projet mais est nécessaire si on souhaite élargir les sources de données et leurs traitemens postérieurs.
L’enrichissement est plus intéressants :
author,content,language,number_of_words,tweet_length,number_of_url,get_number_of_hashtags,sentiment_score
10_GOP,"""We have a sitting Democrat US Senator on trial for corruption and you've barely heard a peep from the mainstream media."" ~ @nedryun https://t.co/gh6g0D1oiC",English,24,156,1,0,0.0
10_GOP,"""We have a currently serving Democratic US senator facing corruption charges, yet there has been minimal coverages of it in the mainstream media."" ~ @nedryun https://t.co/gh6g0D1oiC",English,26,181,1,0,0.0
sonataz45,Just witnessed the most breathtaking sunset. Nature's artwork never fails to amaze me. #NatureBeauty #SunsetMagic,English,15,113,0,2,0.3574
Plusieurs champs ont été ajoutés :
number__of_words : le nombre de mot que contient le tweet.
tweet_length : le nombre total de caractère que contient le tweet.
number__of_url : le nombre d’url que contient le tweet.
get__number__of_hashtags : le nombre d’ashtags que contient le tweet.
sentiment_score : le score de sentiment (compris entre -1 et 1), expliqué plus haut dans l’article.
Cette étape ajoute de la donnée à ce qui existe déjà. Les données vont ensuite être regroupées par auteur et des calculs statistiques vont être effectués, c’est la corrélation. Les données ci-dessous sont difficilement lisibles, notez seulement qu’elles seront ensuite utilisées par l’outil de visualisation.
author,rewteet_sum,retweet_mean,number_of_words_sum,number_of_words_mean,number_of_words_min,number_of_words_max,number_of_words_std,language_count,number_of_hashtags_sum,number_of_hashtags_mean,number_of_hashtags_min,number_of_hashtags_max,number_of_hashtags_std,number_of_url_sum,number_of_url_mean,number_of_url_min,number_of_url_max,number_of_url_std,tweet_length_sum,tweet_length_mean,tweet_length_min,tweet_length_max,tweet_length_std,url_by_words_sum,url_by_words_mean,url_by_words_min,url_by_words_max,url_by_words_std,message_similarity_mean,message_similarity_min,message_similarity_max,message_similarity_std,sentiment_score_mean,sentiment_score_std
10_GOP,0,0.0,50,25.0,24,26,1.4142135623730951,1,0,0.0,0,0,0.0,2,1.0,1,1,0.0,337,168.5,156,181,17.67766952966369,0.08012820512820512,0.04006410256410256,0.038461538461538464,0.041666666666666664,0.002266367888418416,0.6754878323160571,0.6754878323160571,0.6754878323160571,0.0,0.0,0.0
sonataz45,0,0.0,15,15.0,15,15,,1,2,2.0,2,2,,0,0.0,0,0,,113,113.0,113,113,,0.0,0.0,0.0,0.0,,1.0000000000000007,1.0000000000000007,1.0000000000000007,,0.3574,
C’est ici que rentrent en jeu les indicateurs. En effet, nous avons extraits de la littérature scientifique les indicateurs pertinents pour de la détection de manipulation de l’information, par rapport aux données dont nous disposions. Ces indicateurs sont les suivants :
retweet : est-ce que le tweet est un retweet (réponse à un tweet) ou non.
number__of_words : voir au-dessus.
language_count : le nombre de langage différents utilisés par un compte.
number__of_hashtags : voir au-dessus.
number__of_url : voir au-dessus.
tweet_lenght : voir au-dessus.
url__by_words : fréquence des urls dans les tweets d’un compte.
message_similarity : similarité des messages d’un compte.
sentiment_score : voir au-dessus.
Pour chaque indicateurs, nous avons calculés :
la somme
la moyenne
le minimum
le maximum
l’écart-type : indique si les données sont homogènes ou dispersées par rapport à la moyenne.
Visualisation #
La visualisation est l’étape finale qui permettra à un analyste d’investiguer et de conclure à une éventuelle manipulation de l’information. Pour cette étape, nous avons choisi la suite ELK, qui est un logiciel qui permet l’ingestion, le traitement, l’indexation et l’affichage de larges volumes de données.
Cette suite comporte plusieurs outils mais seul Kibana (visualisation) est important ici. Ce logiciel permet de construire des tableaux de bords dynamiques. La majeure partie du travail consiste à construire une représentation pertinente, intuitive et non biaisée. Nous avons pu construire des tableaux de bords rudimentaires que nous vous partageons ici. Une exploration plus approfondie des résultats est à prévoir afin de déterminer la pertinence de nos indicateurs par rapport au jeu de données.
L’objectif de la visualisation est double : elle doit permettre à la fois de dresser rapidement un portrait global du dataset, mais aussi d’être plus fin pour lever des doutes et/ou de comprendre comment la manipulation de l’information s’organise et qui en sont les auteurs.
Approche globale et visuelle #
Une représentation graphique implique une compréhension plus aisée au détriement d’une perte d’information. Nous avons choisi de représenter l’utilisation des langues dans le dataset. Kibana propose une gamme variée de représentation graphique, cette balance entre approximation et visualisation est à garder en tête.
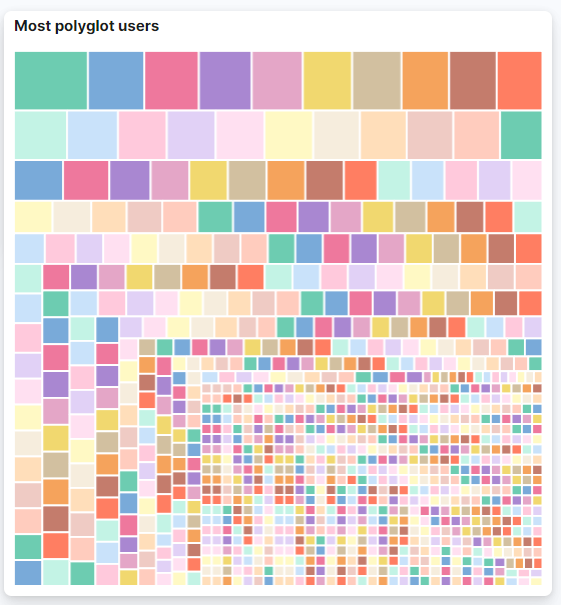
Cette représentation est intéressante ; on comprend que nous sommes en présence de comptes qui parlent beaucoup de langues (rectangles les plus gros). En passant le curseur sur un rectangle, on obtient le nombre de langues parlées (42 pour le rectangle tout en haut à gauche) et son pseudo. Les rectangles situés vers le bord en bas à droite sont des utilisateurs qui n’utilisent qu’une seule langue dans tous leurs tweets. Des utilisateurs avec de nombreuses langues parlées peuvent être des acteurs de la désinformation.
Cependant, il ne serait pas prudent de les classer comme tels à partir de ce seul indicateur mais cela n’est pas la vocation d’une représentation globale. Une investigation plus fine est à prévoir lorsque cette première étape remonte des informations intéressantes.
Approche fine sur un indicateur : l’utilisation des hashtags #
Nous avons construit un dashboard centré sur les hashtags. Il est également possible de construire les mêmes visualisations sur d’autres indicateurs.
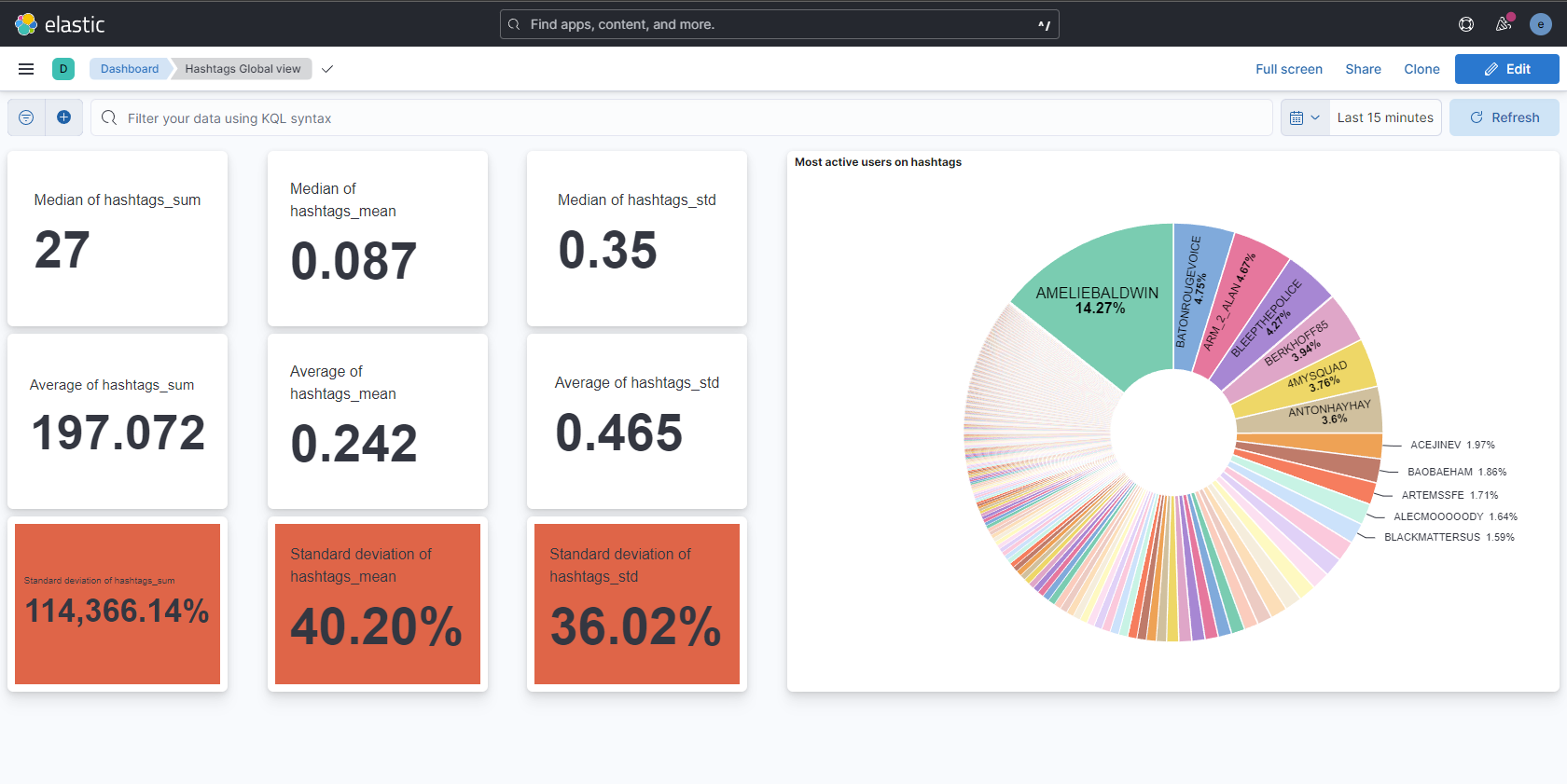
Nous souhaitons que l’analyste ait une vue globale rapidement. C’est pourquoi nous avons coloré en rouge (la couleur est indépendante de la valeur) trois cases. De gauche à droite : l’écart-type (ET) de la somme des hashtags de chaque compte, l’ET du nombre moyen d’hashtags par compte et l’ET de l’ET des hashtags pour chaque compte. En d’autres termes, ces données nous indiquent la disparité de l’utilisation des hashtags par les utilisateurs de notre dataset.
Des chiffres importants, comme c’est le cas ici, indiquent que des comptes utilisent beaucoup de hashtags, tandis que d’autres en utilisent peu. Par exemple la case en bas à gauche montre un ET de 114 366% il y a donc des comptes qui utilisent énormément plus de hashtags que d’autres. Cependant, cet indicateur n’est pas suffisant car on peut imaginer des comptes automatiques mais pour autant légitimes (information en continue par exemple) qui twitteraient beaucoup en utilisant des hashtags. Pour équilibrer cet indicateur, on peut regarder celui à sa droite qui renseigne sur la proportion de hashtags par tweet. On observe un ET de 40% qui suggère que des comptes utilisent plus de hashtags par tweets que d’autres.
Enfin, le graphique nous indique les utilisateurs les plus prolifiques en utilisation d’hashtags. C’est en quelque sorte une équivalence graphique de la partie gauche du tableau de bord. On observe effectivement que quelques comptes sont à l’origine de la plupart des hashtags. On peut également obtenir les pseudos des comptes. Kibana offre la possibilité de cliquer sur un pseudo pour obtenir des informations qui lui sont propres. Ainsi, avec un dashboard adapté, il serait possible d’investiguer directement, à partir d’un seul dashboard, sur un compte précis.
Ce dashboard est un exmple pour un seul indicateur. Un tableau de bord global, qui regrouperait les indices les plus pertinents pour tous les indicateurs, serait utile à un analyste. Un travail reste à effectuer pour choisir les données à afficher.
Evaluation de nos résultats #
Les représentations précédentes se basent sur le dataset mixé (signal + bruit) qui correspondrait à un cas réel. Pour évaluer la pertinence de nos indicateurs, nous avons envoyé à Kibana trois datasets :
le dataset qui contient uniquement des tweets identifiés comme étant à l’origine de campagne de désinformation : le signal (colonne de gauche).
le dataset cas réel qui comporte le signal et le bruit (colonne du milieux).
le dataset qui contient uniquement le bruit, donc des tweets légitimes (colonne de droite).
Nous avons construit un tableau de bord pour évaluer certains indicateurs.
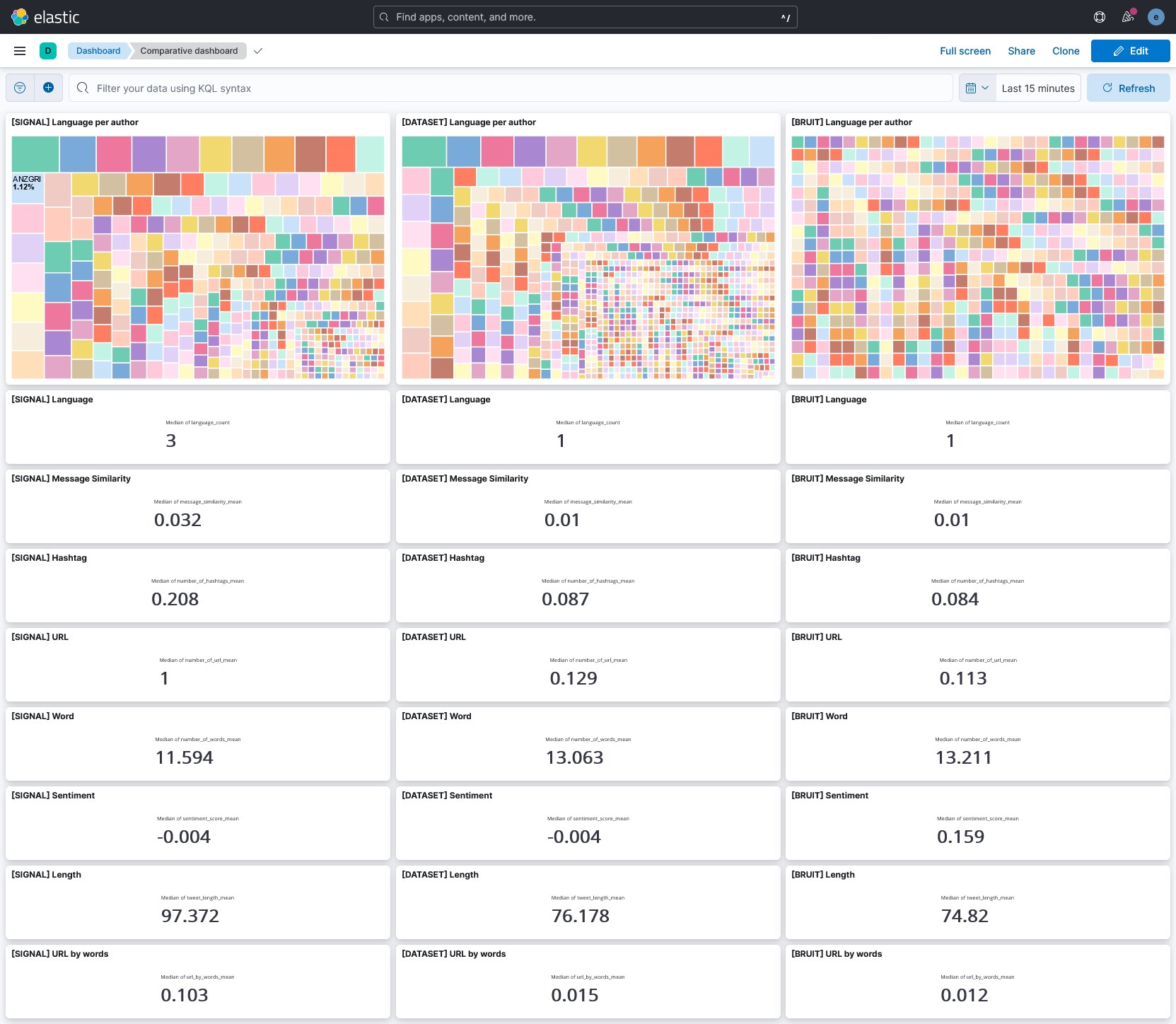
Cette représentation est pour nous la plus intéressante car elle permet de critiquer les indicateurs :
le nombre de langues utilisées semblent être très discriminant, les comptes légitimes ayant plutôt tendance à parler une ou deux langues, alors que ceux qui pratiquent la désinformation sont bien plus hauts, jusqu’à 40 langues différentes.
la similarité des messages est trois fois plus élevée lorsqu’il s’agit de comptes illégitimes.
le nombre médian de hashtags est plus de deux fois plus élevé lorsqu’il s’agit de comptes illégitimes. Cependant, cela ne se reflètent pas lorsque des comptes légitimes sont présents. Cet indicateur est donc à raffiner.
il en est de même pour la présence des URLs. Cela semble être un indicateur très pertinent (facteur 10 entre compte légitimes et illégitimes) mais qui ne se reflète pas beaucoup dans le dataset final. Il semble être prometteur mais est à affiner.
le nombre de mot est peut-être pertinent, on observe une petite différence : 11.594 pour le dataset signal contre 13.211 pour le bruit. Il faudrait explorer plus avant cet indicateur pour savoir si cet écart est significatif.
le sentiment global semble être pertinent, les comptes illégitimes tendent à être moins positifs que les comptes légitimes. On notera que les comptes légitimes ont tendance à être plutôt positifs.
les tweets sont en moyenne plus longs pour les comptes illégitimes.
les comptes illégitmes utilisent en moyenne dix fois plus d’URLs par mots que les comptes légitimes.
Cette approche comparative, bien qu’imparfaite de part la construction de notre dataset “cas réel”, montre plusieurs choses :
certains indicateurs semblent être discriminants pour différencier un dataset contenant de la manipulation d’un dataset n’en contenant pas.
certains indicateurs semblent pouvoir être utilisés pour discriminer un compte plutôt qu’un dataset.
une représentation graphique bien choisie peut faire gagner un temps précieux à un analyste.
il serait intéressant d’entraîner un modèle de machine learning sur ces données qui classerait les comptes selons s’ils sont identifiés comme légitimes ou non. Ainsi, on pourrait construire la heat map de ce modèle et la comparer avec les résultats ci-dessus. De nouveaux indicateurs pourraient émerger.
Comparaison par rapport à une approche “à la main” #
Nous supposons que l’analyste va rechercher les mêmes indicateurs que nous en suivant une méthode similaire. L’outil dont il dispose est un interpréteur Python (ou autre langage de scripting haut niveau) avec des librairies adaptées telles que Pandas, Matplotlib et Nltk. Ce sont les librairies que nous avons utilisées. L’analyste débute avec un dataset bruité et potentiellement hétérogène.
La première étape, et la plus laborieuse, est d’homogénéiser ces données. Il va donc ouvrir le fichier, supprimer les colonnes qui ne lui seront pas utiles, modifier le format de certaines données… Cette étape est obligatoire, même pour notre outil, comme on ne peut pas prévoir les données qui seront envoyées.
La seconde étape consiste à enrichir la données. Pour cela l’analyste va de nouveau utiliser Pandas ou adopter une approche plus naïve et sensiblement plus longue s’il ne maîtrise pas l’outil. De même, s’il ne maîtrise pas les concepts de NLP, l’utilisation de Nltk peut être difficile et produire des résultats incorrects si le pre-processing n’est pas effectué correctement.
Ensuite, il va devoir corréler les données et les aggréger sur les auteurs. Sans Pandas, cela sera long et fastidieux, surtout pour calculer les indicateurs et leurs statistiques (moyenne, écart-type,…).
L’étape suivante est de définir une visualisation pertinente des données. Enfin, il pourra visualiser ses résultats grâce à Matplotlib ou un autre outil, comme Kibana.
Cette approche “à la main” montre que notre outil est pertinent. En effet, l’approche est laborieuse, longue, nécessite un travail de réflexion en amont sur la structure des données et suppose des connaissances dans plusieurs domaines. Notre outil permet de gagner du temps pour se concentrer l’investigation. Avec une solution de visualisation clef en main (modèles de dashboards pré-conçus), notre outil deviendrait encore plus avantageux par rapport à une approche à la main. Nous discutons de cet axe d’amélioration dans la partie suivante.
Perspectives d’amélioration #
Dans le but d’obtenir un outil complet, il faut pouvoir récolter la donnée. C’est aujourd’hui un facteur limitant, aussi car la qualité de la donnée influe directement sur la pertinence de nos résultats. Une collecte de donnée automatique sur des thématiques précises améliorerait la détection de campagne de désinformation. Cette donnée peut être issue de Twitter ou non. Une collecte de données hors Twitter impliquerait une refonte de nos scripts et l’élaboration d’une nouvelle base sur les données ingérées par l’outil. Cependant, les campagnes de désinformations ayant tendance à emmener les utilisateurs vers d’autres réseaux, une collecte plus large permettra de mieux comprendre les méthodes de manipulation.
De plus, la NLP ne s’occupant que de l’anglais, le support d’autres langues élargirait le périmètre de l’outil. Une nouvelle étude des modèle supportant et reconnaissant d’autres langages est à prévoir.
Etant donnée la difficulté et la qualité des datasets disponibles en ligne, un travail d’expérimentation avec des algorithmes d’apprentissage non-supervisé est à prévoir 2.
Enfin, un travail sur la visualisation de donnée est obligatoire pour améliorer l’analyse. Nous avons construit des affichages rudimentaires qui permettent d’obtenir un premier apperçu mais qui sont perfectibles. Une meilleur visualisation permettra une meilleure analyse. Ce travail doit être mené avec précaution pour éviter les biais et les mauvaises interprétations des résultats.
Remerciements #
Nous tenons à remercier notre professeur encadrant, M Guillet qui nous a accompagné tout au long de cette année. Il nous a permis de remettre en question certains de nos choix et à fait preuve d’exigence à notre égard. Nous tenons également à remercier chaleureusement l’équipe d’expert de la DGA-MI qui a eu la gentillesse de prendre le temps de nous recevoir pour répondre à nos questions. Ce projet n’aurait pas la même saveur sans toutes les personnes qui nous ont accompagnées.
Bibliographie #
1. Islam, Md Rafiquel, Shaowu Liu, Xianzhi Wang, and Guandong Xu. n.d. “Deep learning for misinformation detection on online social networks: a survey and new perspectives.” Springer. 10.1007/s13278-020-00696-x.2. Orabi, Mariam, Djedjiga Mouheb, Zaher Al Aghbari, and Ibrahim Kamel. 2020. “Detection of Bots in Social Media: A Systematic Review.” 10.1016/j.ipm.2020.102250.3. Tuna, Tayfun, Esra Akbas, Ahmet Aksoy, Muhammed Abdullah Canbaz, Umit Karabiyik, Bilal Gonen, and Ramazan Aygun. 2016. “User characterization for online social networks.” 10.1007/s13278-016-0412-3.4. Alonso, Miguel, David Vilares, Carlos Gomes-Rodriguez, and Jesus Vilares. 2021. “Sentiment Analysis for Fake News Detection.” 10.3390/electronics10111348.5. Nausheen, Farha, and Sayyada Hajera Begum. 2018. “Sentiment Analysis to Predict Election Results Using Python.” 10.1109/icisc.2018.8399007.Ressources additionnelles #
L. Linvill, Darren, and Patrick L. Warren. 2018. “Troll Factories: The Internet Research Agency and State-Sponsored Agenda Building.” https://www.davidpuente.it/blog/wp-content/uploads/2018/08/Linvill_Warren_TrollFactory.pdf.
Shu, Kai, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu. 2017. “Fake News Detection on Social Media: A Data Mining Perspective.” 10.1145/3137597.3137600.
Contact #
Si notre projet vous intéresse ou que vous avez des questions ou remarques, n’hésitez pas à nous contacter via cette adresse mail. Nous essaierons de vous répondre rapidement : contact.netcheck@gmail.com